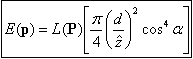|
Departamento de Informática PUC-Rio Programa de Mestrado em Computação Gráfica REALIDADE VIRTUAL AUMENTADA E COOPERATIVA UM PROTÓTIPO DE SISTEMA DE VISÃO COMPUTACIONAL APLICADO A REALIDADE AUMENTADA (ÑAUSA) Aluno: Michel Alain Quintana Truyenque
|
||||||||||||||||||||||||||||||||||||||||||||||
|
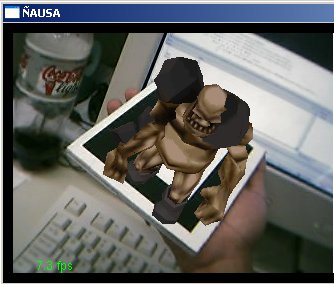
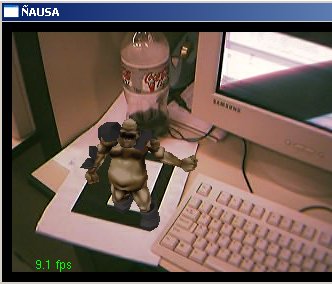
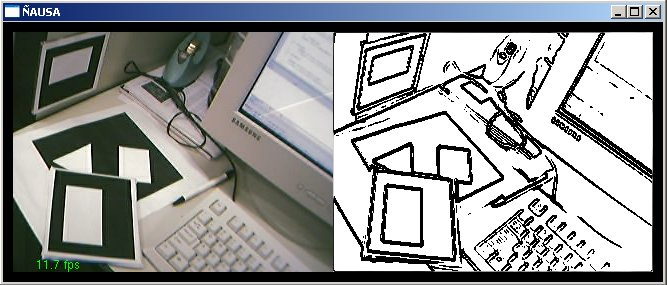
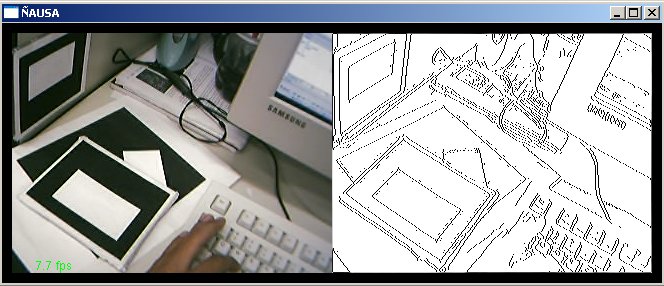
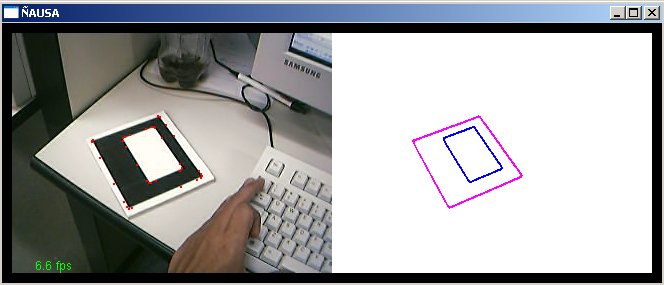
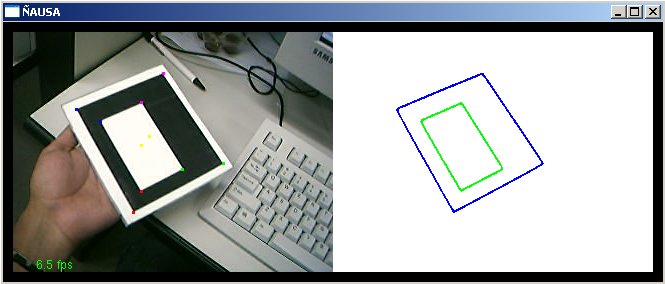
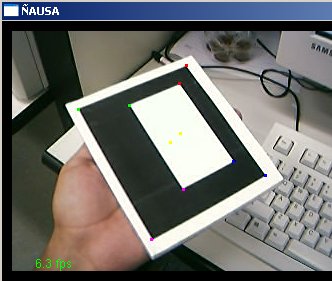
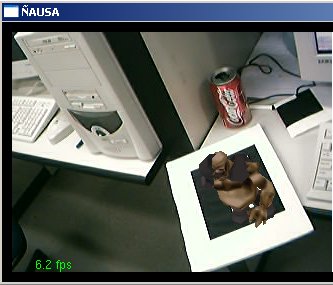
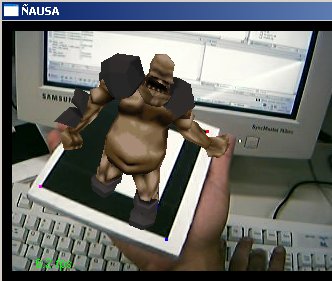
O presente trabalho teve por finalidade estudar, aplicar, testar e pesquisar técnicas de visão computacional em imagens geradas a partir de dispositivos de captura, como são câmeras de vídeo (webcams) e câmeras fotográficas, para aplicações em Realidade Virtual Aumentada. O presente trabalho aborda algumas técnicas de visão clássicas e outras novas e técnicas de processamento de imagens para o tratamento das imagens capturadas. Particularmente este trabalho desenvolve uma aplicação de visão computacional baseada no reconhecimento de padrões para aplicações de Realidade Virtual Aumentada, assim a finalidade do trabalho é: dado um padrão conhecido no mundo, reconhecer o padrão e desenhar objetos 3D acima do padrão, note que não só é desenhar se não ele deve dar a impressão que ele está mesmo, acima do padrão; podemos exemplificar isto mostrando algumas imagens que mostram os resultados finais obtidos. Nas figuras a continuação se mostram em resumo todo o processamento que é feito neste trabalho, no primeiro passo temos a imagem capturada (acima esquerda), aquela imagem passa por um processamento para tentar descobrir o padrão conhecido (acima à direita), uma vez tendo o padrão reconhecido e a traves de algoritmos de render e calibração de câmera, que serão explicados mas para frente, o padrão é detectado dentro da imagem e os objetos virtuais são desenhados acima dele, como é nosso caso um boneco. (embaixo à esquerda). Cada um dos processamento feitos e técnicas utilizadas para o processamento de visão dentro das imagens serão detalhadas nas seguintes sub secções, ajudando a ter uma idéia melhor de como estes resultados, foram conseguidos.
A captura da imagem foi feita num formato de vídeo a 30 fps, o conjunto de frames foi representado como cadeias de bytes, representando assim cada uma das imagens capturadas. Para facilitar o trabalho de captura foram utilizadas as bibliotecas de captura imcapture que disponibiliza funções de captura para diversos formatos e dispositivos de captura de imagens. Esta biblioteca e como ela é utilizada serão disponibilizados junto com o presente projeto na seção de download.
3. CORREÇÃO DA DISTORÇÃO RADIAL E DA ILUMINAÇÃO Muitos dispositivos de Captura principalmente aqueles baseados no modelo convencional de câmera "pinhole", são baseados em lentes. Estes dispositivos embora sejam da era digital ainda tem os mesmos problemas em relação aos anteriores dispositivos, dois desses problemas são, a distorção radial que é proporcionada pela lente e o outro problema é o decremento da iluminação em relação ao centro do foco da imagem. No processo inicial do presente trabalho esses problemas estiveram também presentes e foram tomadas algumas ações, foram desenvolvidos alguns algoritmos para tentar atenuar esses problemas. Uma das soluções no processo inicial do projeto foi fazer testes para conhecer a natureza de nossos dispositivos de captura e tentar conhecer os parâmetros intrínsecos e extrínsecos principalmente das câmeras de captura de vídeo. Baseados nas formulações da equação fundamental da Radiometria e formação de imagens (Ver Trucco e Verri), é possível expressar uma equação do decremento da iluminação em relação a distancia ao centro da imagem. O problema ainda esta em achar o centro da imagem, mas existem modelos que aproximam este erro baseados em correlações de posições reais e posições da imagem do mesmo padrão. As formulas utilizadas no presente trabalho foram :
Testando com padrões do tipo:
Resultados: Nas imagens abaixo claramente pode-se ver a distorção radial presentes no dispositivo de captura. Baseados nas formulações anteriores que são detalhadas no Trucco e Verri construiu-se um algoritmo que dada uma imagem com estas distorções tenta diminuir a distorção radial quanto a do decremento da iluminação em relação a o centro da imagem. Do lado esquerdo se mostram imagens capturadas com a distorção presente e ainda perceptível, e do lado direito as mesmas imagens depois da correção radial e de luminosidade aplicadas.
4. ELIMINAÇÃO E ATENUAÇÃO DO RUÍDO O ruído é uma característica típica que introduzem os dispositivos de captura, fazendo com que as imagens capturadas tenham um ruído aleatório que é preciso eliminar o pelo menos ser atenuado. Para fazer isto e possível utilizar alguns filtros dependendo da natureza do ruído introduzido no processo de captura. Uma vez tendo a imagem com a correção radial e de luminosidade é preciso atenuar o ruído, para isto foram testados vários filtros entre eles os chamados de sal e pimenta, mediana e gaussiana. O filtro escolhido para a atenuação de ruído nas imagens foi o gaussiano 3X3 , este mostrou bom desempenho e os resultados que foram obtidos se mostram nas figuras a seguir. Nas imagens embaixo, mostra-se a aplicação do filtro de atenuação do ruído, gaussiano, embora seja muito pouco perceptível e importante escolher um filtro não muito forte e também que leve muito tempo de execução, já que os outros filtros testados ficaram muito lentos com qualidades bem parecidas ao filtro gaussiano 3x3. As imagens á esquerda são imagens da captura, as imagens da direita são imagens com ruído atenuado e com correção radial e de iluminação.
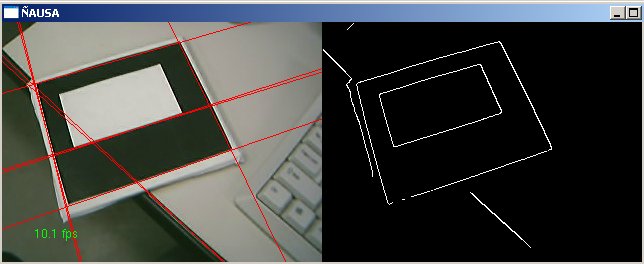
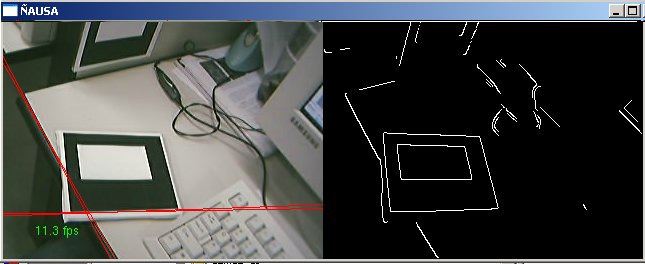
5. DETECÇÃO DE BORDAS NAS IMAGENS Dentro da importância da detecção de características relevantes numa imagem, existem muitas técnicas conhecidas e novas para tentar descobrir características relevantes ao nosso problema, certamente a detecção de bordas numa imagem e o primeiro passo e é um passo importante, como o começo de um problema e uma solução importante para o processo de reconhecimento de padrões em imagens. A detecção de bordas numa imagem é uma técnica principalmente baseada na detecção da diferencia de intensidades luminosas entre regiões vizinhas no plano da imagem analisada. Quer dizer que são algoritmos analisando a natureza da imagem tentando descobrir regiões onde o a variação da diferencia entre regiões vizinhas é grande. Este processo pode ser feito a traves de derivadas, mas temos nas imagens dados discretos, então e possível aplicar as formulações de gradiente em forma de filtros para poder achar aquelas diferencias procuradas nas imagens. Uma vez que temos a imagem com a correção radial e a atenuação do ruído e possível aplicar algoritmos de detecção de bordas nas imagens, os algoritmos testados foram o algoritmo de Sobel e o de Canny cada tem tendo as sua vantagens e desvantagens. Nesta face de detecção o algoritmo escolhido foi o algoritmo de SOBEL pelas características da imagem que produz com um valor de threshold=240, que ajudaram ao bom desenvolvimento dos algoritmos dos processos posteriores principalmente pela boda grossa como aparecem as linhas na imagem filtrada pelo algoritmo de Sobel.
O algoritmo é baseado na aplicação de um filtro de convolução na imagem que combina gradiente e atenuação de ruído, uma das principais vantagens e que é fácil de se implementar em código, é rápido comparado como os outros. - desvantagens As desvantagens são, na qualidade da imagem gerada que é um pouco mais tosca e não muito refinada. Muito sensível ao ruído e iluminação. Depende muito do parâmetro de threshold sendo difícil estabelecer um parâmetro bom para diferentes casos, que não exclua características importantes e exclua ruídos e características menos importantes nas imagens analisadas. No presente trabalho foi implementado e testado o algoritmo de Sobel, e os resultados mostram-se nas imagens a seguir. Foi utilizado o valor de threshold =240, já que nos testes mostrou um bom desempenho na ajuda aos processos posteriores á cadeia de processamento da imagem.
É um algoritmo tedioso de ser implementado requer muitos parâmetros internos para sua execução, não trivial de ser implementado. Lento em tempo de execução. Depende muito também do parâmetro de thresholding, e muito mais sensível do que o Sobel e é difícil de se estabelecer um valor que elimine muitas características não desejáveis e mantenha o importante no modelo. Vantagens A qualidade da imagem gerada na sua maioria tem características desejáveis dos padrões do medelo. Produz muita informação além dos pixels da imagem.
6. DETECÇÃO DE CARACTERÍSTICAS NA IMAGEM A detecção de características é uma das faces mais importantes e também mais difíceis. No presente trabalho foram implementados es testados alguns métodos e algoritmos para identificar características relevantes nas imagens. No decorrer deste passo foram testados alguns desses métodos e alguns deram sucesso e outros não, mas dependeram muito da aplicação e do tipo dos padrões presentes nas imagens. Entre os métodos e algoritmos implementados foram testados, o algoritmo de detecção de cantos e o algoritmo de detecção de linhas mostrados no livro de Trucco e Verri , depois será apresentado uma outra abordagem nova, aplicada principalmente á aplicação desenvolvida neste trabalho, baseada em componentes conexas dentro das imagens. Todos estes métodos geralmente precisam de imagens processadas nos passos anteriores como entrada para seus processamentos, então antes de entrar neste passo e fundamental ter percorrido os passos anteriores. A continuação mostra-se as experiências durante a implementação destes algoritmos.
O algoritmo implementado é o especificado no livro de Trucco e Verri. Como uma primeira abordagem na detecção de características foi testado o algoritmo, para poder detectar os padrões presentes nas imagens. Vantagens
Desvantagens
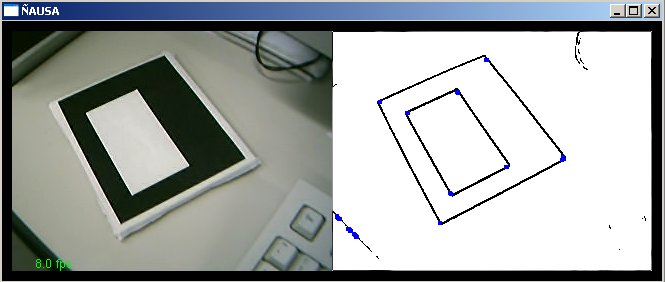
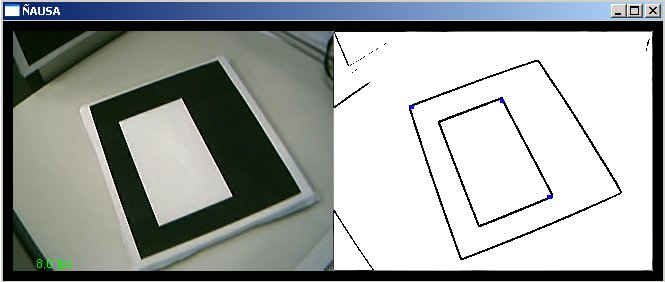
Em geral a estabilidade do algoritmo simples e muito pobre, no caso nosso existiu um problema grave em definir os parâmetros que tenha um desempenho aceitável, tendo muitos problemas na detecção correta dos cantos presentes nas imagens, fazendo desta maneira difícil o processo de reconhecimento. Uma solução poderia ser algumas melhorias e até algoritmos com melhorias existentes, mas a complexidade aumenta e faz um fator critico em aplicação de tempo real. Nas figuras a seguir mostram em resumo o desempenho do algoritmo de detecção de cantos, os conjuntos de pontos azuis representam possíveis cantos detectados dentro da imagens da esquerda. O importante é perceber que o desempenho é bem diferente para diferentes posições da câmera, como se mostra nas figuras, por exemplo vemos que o desempenho na posição da figura c-2 é razoável, mas se mexemos um pouquinho a câmera como na figura c-3 o desempenho cai e a detecção se torna muito difícil pela estabilidade apresentada pelo algoritmo, embora esse problema possa ser tratado restringe muito a câmera a permanecer perto do padrão, já que se afastamos a câmera como na figura c-1 o desempenho cai muito e torna muito difícil a detecção correto ou aproximado dos cantos.
Uma outra abordagem diferente foi fazer a detecção das características mediante a detecção das linhas presentes no padrão. O algoritmo de Hough do Trucco e Verri foi implementado com algumas melhorias que se explicam a continuação. Vantagens
Desvantagens As desvantagens apresentadas a continuação dizem só aquelas que a transformada de hough teve no presente trabalho, não são generalizáveis para todas as aplicações.
Distintas posições da câmera mostram que quando permanece-se perto padrão o desempenho do algoritmo é bom já que com um processamento posterior que acredito não seria fácil de fazer pode se chegar a reconhecer o padrão, as figuras h-1 e h-2 mostram estes fatos fazendo a diferencia da saída do algoritmo para posições da câmera, por tanto para aplicações de câmera estica o em movimento que precisem estar perto do padrão é uma alternativa muito boa. A figura h-3 mostra uma das coisas que o algoritmo pode fazer o reconhecimento das linhas ainda com alguns objetos acima o na frente do padrão.
A Idea de componentes conexas veio do objetivo de restringir a análise da imagem só na região ocupada pelo padrão, mas como fazer aquilo?. As componentes conexas são conjuntos de pixels da mesma cor na imagem que aparecem juntos e definem alguma geometria dentro da imagem, como podem ser curvas, polígonos etc. Aqui temos a idéia de componentes conexas fechadas por exemplo são aquelas que sua forma é definida por uma curva fechada. Uma abordagem que deu certo para identificar a região de interesse dentro da imagem foi o reconhecimento de componentes conexas fechadas.
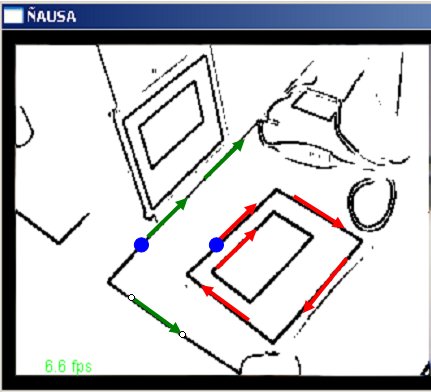
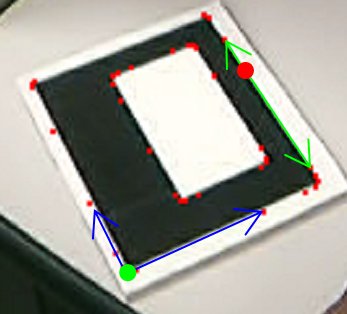
Uma vez que temos a saída do algoritmo de sobel temos a imagem em formato binário, preto e branco, então para cada pixels preto na imagem identificamos a componente conexa ao qual ele pertence, definindo famílias de componentes conexas, uma vez tendo estas componentes conexas vemos se elas são fechadas ou não, assim podemos descartar as que não são fechadas. A idéia e simples e simplesmente partir de um ponto qualquer da componente assumir uma direção de percorrido e ver se podemos chegar ao lugar de partida por outro caminho. O algoritmo foi implementado como um algoritmo recursivo que acha as componentes conexas e as valida se elas são componentes conexas fechadas. O algoritmo para achar as componentes conexas fechadas parte de um principio básico, já que temos a entrada da imagem como una coleção de bits queremos achar o conjunto de pixels na imagem que definem uma curva fechada. As componentes conexas tem uma particularidade que é ilustrada na figura cc-1, como podemos ver se partimos de um pixels da componente, digamos o ponto azul seguindo a direção das setas vermelhas podemos voltar ao ponto azul onde partimos por um caminho diferente. Uma coisa que não acontece como as outras componentes, exemplo a de setas verdes donde não possível voltar ao ponto azul de partida seguindo a direção das setas verdes.
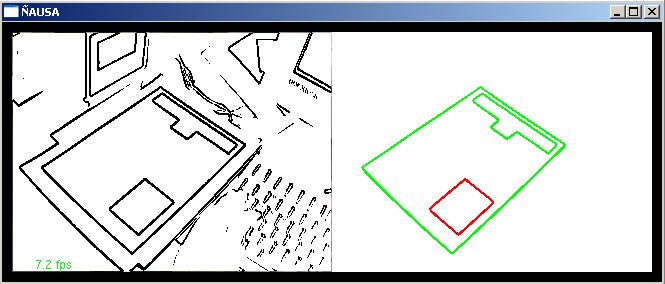
No caso do nosso trabalho como podemos ver o padrão a ser analisado e formado por dos conjuntos componentes conexas fechadas, e uma grande vantagem é que se afastamos a câmera ou temos alguma coisa além do padrão na imagem podemos identificar as componentes conexas fechadas, que já descartam muitas coisas na imagem que estão fora de nosso interesse. Embora seja um método que teve bom desempenho ele é uma heurística que não garante resultados a 100% mas na pratica se mostrou bem aceitável e robusto. Vantagens
Desvantagens
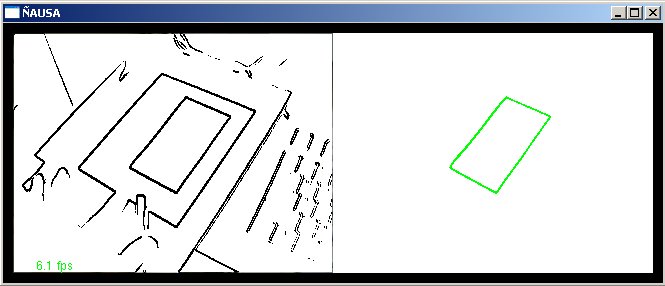
As figuras a seguir mostram graficamente os resultados do algoritmo de componente conexa fechada, e sua capacidade de reconhecimento do padrão como são as figuras cc-3 e cc-3, também se mostra a debilidade deste algoritmo na figura cc-4, a qual mostra o problema que se tem quando existem objetos na frente do padrão.
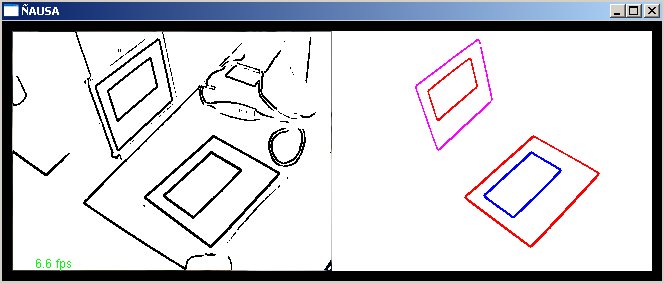
Nosso modelo adotado foi a das componentes conexas fechadas, resultados do passo anterior têm um conjunto de componentes conexas fechadas na representação da imagem que tem que inda analisadas para poder identificar quais delas são realmente do padrão e quais não são. No nosso padrão que consta de dois retângulos, um sempre dentro de outro, podemos ver que os pontos de interesse são os cantos, oito cantos que temos que identificar dentro destes componentes conexos fechados, assim neste passo estamos interessados principalmente em detectar os oito cantos que compõem nosso padrão e ter certeza que os pontos que estamos identificando são inegavelmente os oito pontos do padrão, por tanto neste passo estamos interessados numa saída como a figura p-1.
O processo de achar esses cantos consta de alguns passos até ter certeza que aqueles pontos são realmente os cantos que estamos procurando. Até este passo temos as componentes conexas representados como conjuntos de pontos no plano, dentro de esses pontos encontram-se os cantos que estamos procurando, o passos feitos nesta face do processamento foram.
O fecho convexo certamente pode nos ajudar a reduzir estes pontos em cada componente conexo para um conjunto de pontos na borda, onde os cantos encontram-se com certeza. Antes de realizar este passo que no nosso caso é linear, já que os pontos pela natureza como eles foram lidos da imagem já vêm ordenados do jeito que o algoritmo de fecho convexo chainHull_2D precisa; é feito um passo de pré processamento dos pontos o qual afina a curva da componente conexa levando para o algoritmo de fecho convexo um conjunto menor de pontos. A figura p-2 mostra o algoritmo de fecho convexo aplicado as componentes conexas fechadas, a saída dele como um conjunto de pontos na borda onde os cantos estão com certeza.
Uma vez que achamos o fecho convexo, temos um conjunto de pontos na borda, como mostra a figura p-2, que definem a curva, estes conjuntos de pontos têm pontos de interesse perto dos cantos do padrão , estes pontos são os que se aproximam melhor dos cantos do padrão, podem ser achados calculando o angulo dos vetores que eles definem com o ponto mais próximo a sua direita e a sua esquerda, ângulos razoáveis menores de 120 graus na pratica já dão bons resultados para achar estes pontos como se mostra nas figuras abaixo. A figura p-3 mostra o processo realizado nesta face, para cada ponto formam-se vetores com os seus vizinhos a esquerda e a direita, e analisamos o angulo que estes vetores fazem, no caso da figura os pontos de natureza como a do ponto vermelho são eliminhados e os pontos verdes são mantidos.
Do passo anterior temos ainda um conjunto de pontos, todos acumulados perto dos cantos do padrão, estes pontos são agora de nosso interesse, já que temos vários conjuntos de pontos próximos, cada conjunto próximo dos cantos do padrão, podemos simplesmente um representante de cada um deles, elegendo um deles o fazendo media entre eles. Aqui foi tomado um como representante um deles, a razão que não tinham muitos pontos nos conjuntos, mínimo um e Maximo três nos testes feitos. Até agora então obtemos um resultado como é mostrado na figura p-1. Note que os passos anteriores foram feitos para todas as componentes conexas que tínhamos até este passo, agora temos um conjunto de pontos que representam essas componentes, 4 no caso dos retângulos e outras quantidades em caso de se ter outras componentes conexas a mais, considerando só as componentes com 4 pontos já jogamos for a muitos outros que poderiam aparecer, e se no caso de ainda ter mais de 2 componentes de interesse com 4 pontos também , lembremos que no nosso padrão temos um retângulo dentro de outro, considerando isto podemos agora sim, ter só o conjunto de pontos que representam o padrão dentro da imagem. Até agora temos oito pontos em dois conjuntos de 4 pontos cada um deles, mas qual desses pontos é o da direita do outro?? qual é o ponto que no modelo aparece a esquerda de um outro dado? Este processo é chamado de correlação dos pontos da imagem com os pontos no mundo, e simplesmente é saber qual dos pontos reconhecidos na imagem representa um ponto no padrão que estamos utilizando, este processo é feito no seguinte passo.
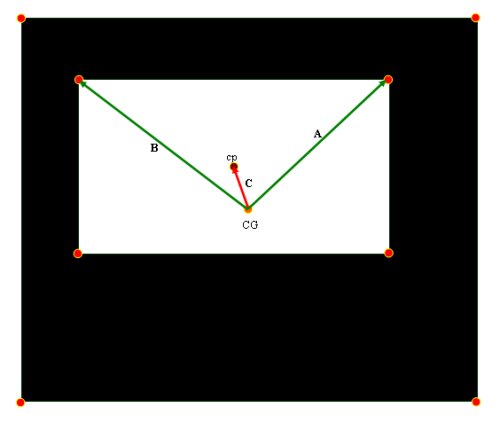
Neste passo temos dos conjuntos de 4 pontos, representando cada um dos retângulos do nosso padrão no mundo. Uma ajuda grande do algoritmo de fecho convexo é que os pontos sempre são dados numa ordem anti-horária. Um primeiro passo foi achar os centros de cada um dos retângulos (ver figura. rc-1), identificar o centro do retângulo grande (CG) e o do pequeno (cp) e formar um vetor que vai do centro do retângulo grande pro o centro do retângulo pequeno. Chamaremos este vetor C. O Segundo passo começando pelo primeiro ponto em cada conjunto de 4 pontos, pegamos ele e o seguinte ponto depôs dele, traçamos vetores (A e B) que vão do centro do retângulo que formam para cada um dos pontos, e fazemos a validação da orientação desse vetores côn relação ao vetor C. Como se mostra na figura rc-1.
Se para cada componente conexa procuramos o ponto i e o ponto i+1 que façam com que AxC e CxA sejam valores positivos, então podemos facilmente unicamente um ponto i e i+1, é com isto já sabemos qual ponto da imagem representa cada ponto no padrão. Assim podemos descobrir a relação de cada um dos pontos da imagem com cada um dos cantos no padrão que estamos trabalhando, e importante dizer que este processo tem que ser feito de uma maneira diferente para cada padrão distinto que tenhamos. Nas figuras rc-2 e rc-3 se mostram os resultados da etapa de reconhecimento do padrão, vemos que os cantos sem importar a posição que eles têm na imagem, sempre tem a mesma cor, significando que o algoritmo esta reconhecendo a orientação dos pontos e sua relação com o padrão exposto na figura rc-1 .Agora sim estamos prontos para o algoritmo de calibração de câmera, que será apresentado no próximo passo.
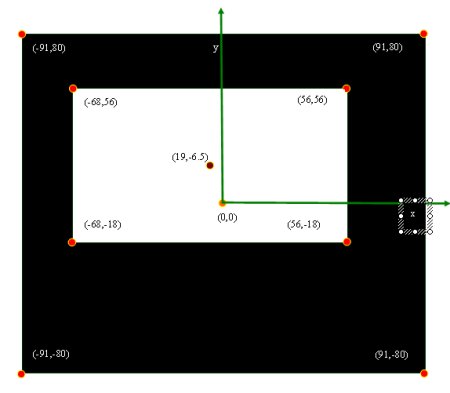
Dentro da finalidade do projeto a calibração de câmera esta imersa dentro da aplicação da Realidade Aumentada, o algoritmo de calibração é de muita utilidade para saber e descobrir quais são os parâmetros intrínsecos e extrínsecos da câmera que esta vendo a cena nesse instante, isto é muito útil se, por exemplo, queremos desenhar algumas cosas virtuais em três dimensões dentro da imagem como se estivera realmente na cena que estamos vendo com a câmera. Já que a finalidade do projeto é uma realidade aumentada, precisamos desenhar coisas virtuais dentro da cena. Para isto utilizamos o algoritmo de calibração de câmera de Tsai para padrões bidimensionais, isto pela natureza de nosso padrão ser plano. Para a entrada do algoritmo de calibração além da correlação entre cada ponto da imagem e cada ponto do padrão, precisamos definir uma medida para cada um desses pontos num sistema de coordenadas como entrada no algoritmo. Para cada um dos pontos achados na imagem podemos manter as coordenadas de pixels de cada um deles, só que com a origem do sistema no centro da imagem. Para os pontos no padrão definimos a origem do sistema como o centro do retângulo maior entre os dois, e as medidas de cada um dos pontos em relação a este centro em milímetros, como se mostra na figura kc-1, aqui também mostra-se a correlação que é feita entre pontos da imagem e do mundo real.
Uma melhora do algoritmo de calibração feita aqui foi a distribuição do erro numa quantidade maior de pontos gerados a partir dos pontos originais de calibração, assim dos 8 pontos de calibração que tínhamos foram gerados 64 pontos novos para distribuir o erro e ter um erro global menor, depois disto foi aplicado também um filtro de Kalmam nos parâmetros da câmera para suavizar o movimento dos pontos de calibração na imagem.
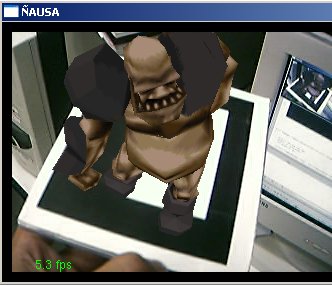
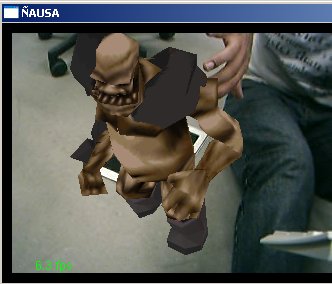
Uma vez calibrados os pontos no algoritmo de calibração de câmera temos já definidos os parâmetros necessários para poder desenhar coisas virtuais na cena. Para isto foi utilizado o sistema baseado no Opengl para poder aplicar os parâmetros da câmera ao desenho de primitivas. No nosso caso desenhamos um boneco 3D de um Mutante para ver ele como se estivesse parado acima do padrão reconhecido. Algumas imagens mostram esse efeito.
A utilização deste código é de completa responsabilidade da pessoa que abaixar o código ou executável, o autor não oferece garantia nenhuma nem se responsabiliza pelos danos que ele possa causar no se equipamentor. Este código é de livre utilização para fines acadêmicos e para fines comercias procure dar os créditos ao autor. Instruções Gerais Estas instruções são para mostrar as funcionalidades do programa "ñausa", mas não implicam uma ordem que se debe seguir para poder no final desenhar boneco. A seqüência correta para chegar sem problema a desenhar o boneco são nesta ordem as teclas " g -> s -> x -> k -> m"
|
||||||||||||||||||||||||||||||||||||||||||||||