
Reconstrução de malhas a partir de fotos estéreos de câmeras calibradas
O objetivo deste terceiro trabalho é a reconstrução tridimensional de objetos a partir de um conjunto de fotografias digitais.
Visão Geral
Para fazermos a reconstrução utilizamos o método de luz estruturada codificada, que consiste em iluminar o objeto a ser adquirido com slides subsequêntes que produzem um padrã codificado.
Foram utilizadas duas câmeras e um projetor de modo que a reconstrução pudesse ser feita apenas com a calibração das câmeras.
A cena onde está presente o objeto a ser reconstruído, é iluminada pelo projetor que gera uma grade de padrões coloridos. A imagem é capturada pelas uma câmeras digital e transferiada para o computador.
De posse dos dados de calibração das câmaras, obtidos por um processo anterior, e dos pontos correspondentes, são calculadas as coordenadas tridimensionais dos pontos, sendo possível a reconstrução do modelo do objeto ou da superfície.
O princípio básico é o mesmo que permite a um sistema de visão binocular (como é o caso de nosso sistema visual) avaliar a distância a que está situado um determinado ponto. Quando uma única imagem está disponível, a posição do ponto na imagem não determina sua posição no espaço: o ponto, no espaço, pode estar em qualquer lugar da reta que une o ponto de vista ao ponto projetado, como ilustrado na Figura 1. Em um sistema binocular, no entanto, são capturadas duas imagens em que o ponto de interesse aparece. Neste caso, são conhecidas duas retas que contêm o ponto correspondente do espaço, que pode, então, ser determinado em um processo chamado de triangulação.
Figura 1: Visão binocular.
O processo de resconstrução consiste basicamente de três etapas:
- Aquisição das imagens.
- Calibração da câmera.
- Processamento das imagens, onde adquirimos os retalhos da superfície do objeto.
- Gerando nuvens de pontos (retalhos).
- Alinhamento dos retalhos.
- Geração da malha.
Nota: Por falta de tempo, as duas últimas etapas não foram efetuadas.
Aquisição das Imagens
Para a reconstrução completa do modelo é necessário que tenhamos fotos de diferentes pontos de vista para que possamos recuperar informação de toda superfície do objeto a ser reconstruído.
Para que a etapa de calibração possa ser realizada, é necessário obter fotografias de um padrão a cada nova posição das câmeras. O padrão utilizado foi do tabuleiro de xadrez.
Em uma primeira tentativa, fotografamos um objeto real em um ambiente controlado. No entanto as imagens obtidas não foram de boa qualidade. As fotos apresentavam alto nível de ruídos e/ou estavam desfocadas. Logo, as etapas seguintes foram bastante prejudicadas - o processo de calibração de câmeras foi incapaz de identificar a maioria dos pontos do padrão utilizado.
Figura 2: Imagens reais.
Sendo assim, a alternativa foi analizar um modelo sintético. Um modelo artificial foi gerado através do software 3DStudioMax e imagens artificiais em diferentes pontos de vista foram renderizadas (Figura 3).
Como vantagens desse processo temos:
- maior precisão na projeção do padrão de cores;
- não há presença de ruídos na imagem;
- as imagens geradas são de alta qualidade.
Figura 3: Imagens sintéticas.
Calibração da Câmera
De modo geral, esta etapa inclui a calibração intrínseca e extrínseca de câmeras e outros dispositovos utilizados. A calibração intrínseca determina os parâmetros dos dispositivos de captura e a calibração extrínseca determina a relação entre os sistemas de coordenadas locais dos dispositivos e o sistema de coordenadas global da cena 3D.
No modelo real tentou-se utilizar o processo de calibração de câmera baseado no algoritmo de Tsai ( implementado no trabalho 2 ). Entretando, este mostrou-se incapaz de identificar corretamente a maioria dos pontos do padrão utilizado.
Em um modelo sintético o processo de calibração de câmera torna-se desnecessário, já que conhecemos a posição da câmera para cada ponto de vista gerado.
Processamento das Imagens
Esta etapa do processo consiste em extrair as informações necessárias de cada imagem do objeto e se subdivide em:





- Quantizar o espaço de cor
Reduzir no espaço de cores das imagens para o espaço de cores utilizado pelo padrão escolhido como mostra a figura abaixo.
Padrões de projeção (3,2)-BCSL
Imagem quantizada.



- Detectar as transições
Detectar contorno das faixas verticais e horizontal.
A busca por transições consistem em um processamento simples em busca de valores de cores diferentes em pixels vizinhos.
- Utilizar
o código proposto por Asla Sá para relacionar os pontos
de direntes pontos de vista
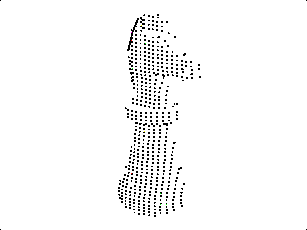 |
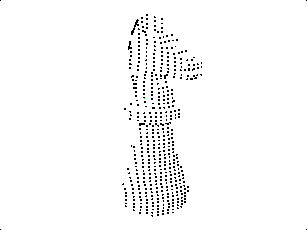 |
Cerando Nuvem de Pontos
Tendo em mãos os pontos obtidos no processo anterior
Para efetuar o processo de correspondencia podemos tulizar duas abordagens:
- Geometria Epipolar
- Triangulação
Geometria Epipolar
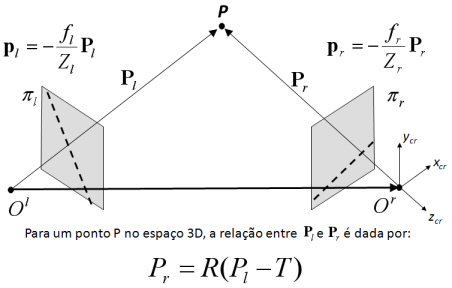
Idéia geral: através da geometria epipolar, queremos determinar o ponto P no espaço onde os raios se intersectam. Faz-se estes cálculos através de uma matriz de transformação geral entre o espaço da câmera e o espaço da imagem.
Dadas duas câmaras colocadas em duas posições distintas no espaço tridimensional, representa-se por Pl e Pr as coordenadas de um ponto P nos referenciais de cada câmara e por pl e pr as projeções desse ponto nos planos imagem πl e πr respectivamente.
Os sistemas de coordenadas associados a cada câmara estão relacionados entre si através de uma transformação de corpo rígido, a qual é definida por um vector de translação T = ( Or -Ol ) e por uma matriz de rotação R.
A Matriz Essencial E
A Matriz Essensial E é uma matriz de rank = 2 que estabalece a interligação entre a resttição epipolar e os parâmetros extrínsecos ( posição e rotação ) do sistema estereo.
A Matriz Fundamental F
Cálculo da Matriz F através do algoritmo dos 8 pontos
Dado um conjunto de pontos correspondetes mas imagens estereo. Cada par de pontos correspondente define uma equação homogênea linear em função dos 9 parâmetros da matrz F. A solução para os 9 parâmetros da matriz F pode ser encontrada para um número de pontos correspondente superior a 8, se estes pontos não apresentarem uma configuração degenerativa. Uma vez que o sistema de equações resultante é homogêneo, a solução obtida é única a menos de um fator de escala.
Considerando um conjunto de pontos correspondentes superior a 8, o sistema é sobredeterminado, e a solução pode ser obtida por SVD ("Sibgle Value Decomposition").
Triangulação
O princípio básico que permite a recuperação de informação de profundidade a partir de imagens é o princípio de visão estéreo. A visão estéreo´e baseada no fato de que se o mesmo ponto X de uma cena
for observado por dois pontos de vista, é possível reprojetar dois raios a partir da imagem na cena que se interseptam no ponto aonde a luz foi refletida pela cena. Esse processo é chamado triangulação.O princípio da triangulação para a reconstrução da posição de um ponto no espaço tridimensional a partir de sua projeção em dois planos de imagem conhecidos é bastante simples.
No caso de interesse, para a triangulação por luz estruturada, uma das câmeras é substiuída por um projetor e o padrão básico de correspondência é constituído por faixas verticais. Nesse caso, o problema de triangulação deve ser resolvido calculando-se a interseção de um raio partindo da câmera com o plano gerado pela faixa de interesse, como mostra a figuta abaixo.
Note que na discussão acima, estamos supondo que os pontos no sistema da camera e do projetor estão em coordenadas normalizadas. Isso significa, em particular, que coordenadas em pixel nas imagens foram devidamente transformadas usando os parametros intrínsecos da câmera, e que foiaplicada a correção da distorção radial.
Ao final desta etapa temos uma nuvem de pontos no espaçõ para cada ponto de vista (retalhos). Os próximos passos são alinhar os retalhos e gerar a malha (ou visualizar os pontos).
Alinhamento dos Retalhos
Nesses retalhos a geometria está descrita em relação ao sistema de coordenadas local do dispositivo. Temos então o problema de alinhar os retalhos em relação uns aos outros dentro de um sistema de coordenadas global. Para realizar o alinhamento podem ser utilizadas informações do sistema de aquisição, correspondência entre pontos característicos do objeto, ou mesmo uma combinação desses dois elementos. Por exemplo, se o sistema de aquisição tem uma base giratória para posicionar
o objeto em relação à câmera, o ângulo de rotação pode ser usado o alinhamento. Também, a determinação de um conjunto de pontos marcantes do objeto, como quinas ou protuberancias, em dois retalhos distintos pode ser usada para calcular o movimento rígido que faz o casamento desses pontos (note que para ser possivel esse casamento, é necessário que os retalhos tenham uma área de inteseção na
superfície do objeto).Normalmente, esse problema é equacionado em duas etapas: na primeira etapa os retalhos são alinhados entre si, aos pares, e na segunda etapa o alinhamento de pares é melhorado considerando todos os retalhos.
Independentemente do método utilizado, seja ele baseado em dados do sistema ou casamento de pontos marcantes, o alinhamento inicial em geral não têm uma precisão satisfatória e precisa ser refinado
usando uma outra técnica. O método mais conhecido para alinhar pares de retalhos é baseado no algoritmo ICP (“Iterative Closest Point”), que iterativamente transforma dois conjuntos de pontos minimizando a distância entre eles.O algoritmo ICP consiste de dois passos que são executados iterativamente até a convergência. Primeiro, pares de pontos correspondentes nos dois retalhos são identificados. Depois um método de otimização computa o movimento rígido que reduz a distância entre os dois conjuntos, no sentido de mínimos quadrados.
Geração da Malha
O problema de geração de malhae é, de modo geral, enunciado da seguinte maneira: dado um conjunto finito de pontos P C R³ gerar uma superf´icie S tal que P C S ou max { ||p - S|| : p pertence à P } é suficientemente pequeno.
Esta formulação acima não é muito precisa porque dá espaçoo a diversas interpretações e é mais classificado como um problema de construção de superfícies. Mas se conhecermos algo sobre a origem da nuvem de pontos P (com por exemplo o seu modelo real) e nosso objetivo é obter uma descrição exata desta superfície no computador, deparamo-nos com o problema de recontrução de superf´icies (Figura 4). O conhecimento sobre a superfície é importante na escolha do melhor algoritmo de econstrução.
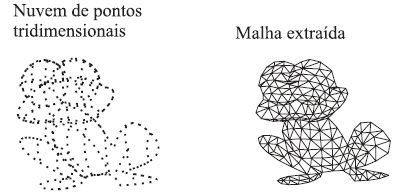
Figura 4: Superfície amostrada e reconstruída.
A maioria dos métodos que propõem uma solução requerem pontos “suficientemente densos” para gerar a superf´icie desejada. Tal suficiência, conhecida como condição de amostragem, deve garantir uma boa aproximação em relação à superfície original, isto é, a superfície reconstruída é homeomorfa e suficiente próxima.Um alternativa éutilizar apenas os pontos e empregar um algoritmo de avanco de frente, como o Ball Pivot, ou mesmo fazer uma triangulação de Delaunay diretamente. No segundo caso, em geral a poligonização é cfeita a partir de uma função implícita associada aos dados volumetricos no espaço da cena.
Resultados
Bibliografia:








- Fotografia 3D; P. C. Carvalho, L. Velho, A. Sá, E. Medeiros, A. A. Montengro, A. Peixoto, L. A. Rivera. Editores: L. Velho e P. C. Carvalho
- Slides do curso.
- Notas de aula.
- TRABALHO 01 - |
-
TRABALHO 02 - |
- TRABALHO 03 - |